sounds way cooler than "AI note taker"
The following was transcribed and corrected by my program – I have not changed it at all. Copy and pasted straight from my brain! So as much as it should be pristine. It’s not. I recommend you watch the video to actually understand what’s going on.
So, if all goes well, I should be using the very tool I’m talking about to write this blog post.
Now, having used the chat function or speech function on ChatGPT, I was completely blown away by the fact that it’s blazingly fast, and it can talk in Jamaican or Roadman. I found it completely fantastic, and it’s the closest thing we’ve ever come to a real-life Jarvis – which, to be honest, is all I’ve ever wanted from an AI.
But there’s a massive problem with this chat function of GPT: It has no access to my personal information, which is a good thing to be honest. However, the only thing I really want a Jarvis for is to make notes and remind me of things. And I don’t really need to ask questions that often. If I do need to know the answer to something, it’s usually just quicker to Google it.
So, I was more concerned with it being able to note stuff in a place where I can access it later – so I can just write down my thoughts as I have them and not have to bother about writing them down somewhere. That’s where I had the idea to use OpenAI’s Whispered Speech-to-Text model, which I played around with in the past, and Meta’s LLaMA model, which I’d also played around with in the past.
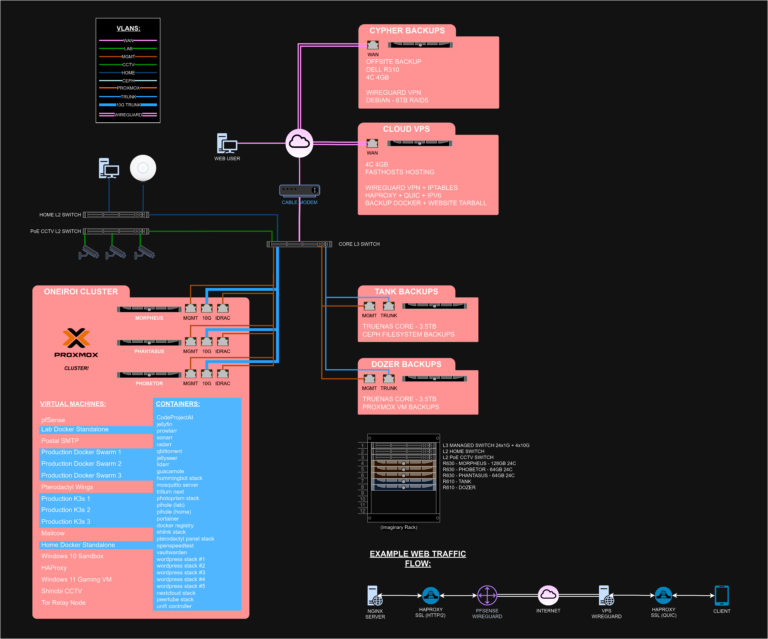
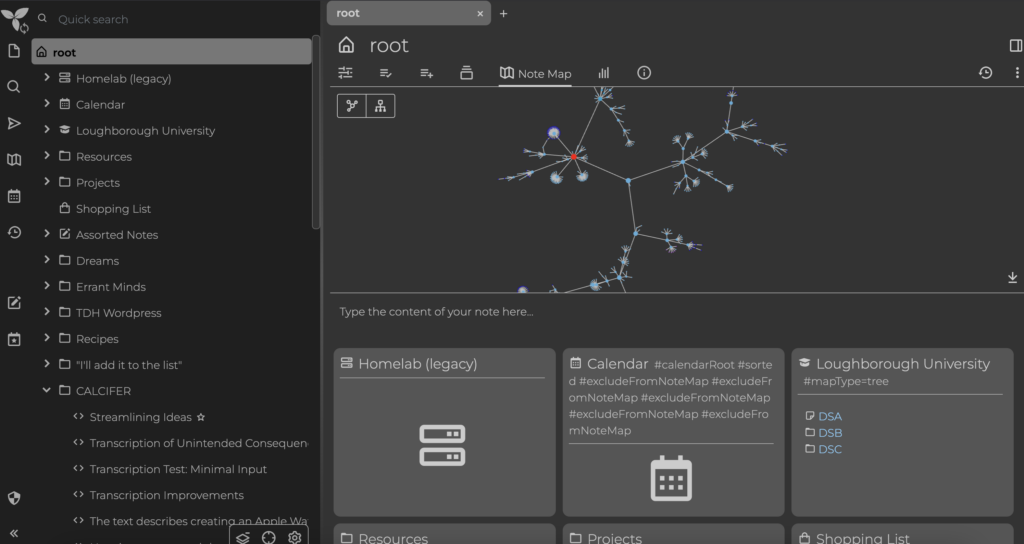
Using some Python code, my plan was to get these models to talk to my notes application that I’ve already been using for about five years – Trillium Notes. If you don’t know about it, it’s fantastic; I highly recommend it. It’s like your own personal Wikipedia. It’s a hierarchical note-taking application, and you can create links between different notes and create an interconnected web of knowledge and thoughts. It’s really fantastic.
So, if I could get some voice-activated tool to make notes for me, then I would have the closest thing to a virtual brain as possible.
So, I could just use a speech-to-text model and write a simple Python script to store it in my Trilium notes via API and call it a day. But the reason I want to integrate Lama into this is because I want it to be smart about how it places notes. If possible, I wanted it to look at the notes I already have, find a subcategory or a subtree that the note would fit well under and place it in that category. So then I could see and find it later. Additionally, I want the titles to be sort of nice summaries that make sense so I can also find it later. And so I can ask it questions about my notes.
Using a large language model in this experiment would greatly elevate its usefulness and ability. But my problem was initially how do I get it to interface with the Trilium API? I initially tried getting it to write API requests, which then the Python script would extract from the response of the LLM and use to actually send the API request.
However, at least with Lama 3.8B, I had problems getting it to construct consistent and non-hallucinogenic API requests. So I instead migrated to using the Python code to generate rigid API requests and then inserting Lama’s output into this API request. That way there would be no malformed requests. I’m still going to look into using this approach on Lama 3.18B-128K because that seems to be much, much better than the 3.8B model.
But I think it would be easier to do it this way. However, it does mean that for each independent task, I have to write logic and code to handle every possibility. However, I did try to get around this by giving the model some local documents that said, “Hey, if I make a note, if I asked to make a note or jot something down or something similar to that, preface your response with this string of numbers.”
The Python code would then pick that up and use that to determine what it was going to do with the LLM output. That was actually very promising. However, I abandoned that approach when I ran into problems later. Although, I think I’ll explore this later because it seemed to work quite well and greatly expands the usefulness and decreases the work I have to put into this code.
**We’re Getting Ahead of Ourselves Here**
We’re getting a bit ahead of ourselves here because the first version I tried was actually to ask the speech-to-text model, generate just the raw input and then pass that to the LLaMA model with the instruction, “clean up,” summarize this, and give it a title in bold at the start. Say absolutely nothing else.
This worked surprisingly well and generated responses that were known on since were really well constructed and were excellent summarizations or corrections of what I said. The title function worked flawlessly. And because the bold title was surrounded by double asterisks (because it’s marked down), I was able to extract that title and use it as the title for the note in Trillium.
This was working fantastically. And it all came crashing down when I tried to improve it.
So, spurred on by this success, I decided to try implementing a wake word so that I didn’t always have to perform the whisper speech-to-text function. It would wait for a specific wake word and then begin the more intensive whisper speech-to-text. I decided on using Porcupine, which is a wake-word model. You need an account and a license key but it’s free to use, and you can even train or create your own custom wake words.
I initially tried “Calcifer,” the name of the flame from Howl’s Moving Castle, but wasn’t able to create a wake word using their online wake-word generator. So, I settled for “Wise Guy” in an American Italian accent, which works fantastically.
That ended up working really well except now for some reason, LLaMA was convinced it was a 30-year-old woman named Sarah who liked hiking, climbing, and reading books and was adamant that she could only do those things and absolutely nothing else. It then started hallucinating completely, spewing out random garbage and gobbledygook.
I still don’t really know why this happened but it was only via the API interface for GPT-4.org, which is the front end for the LLM I’m using. It just makes it very easy because it has an open AI-style API, which means there’s a lot of documentation and it’s just easy to work with.
But I updated GPT-4.org from an earlier version to the latest version, and from that point on, it seemed not to work. I tried downgrading but wouldn’t have it. So, instead, I decided to use still GPT-4.org’s program but instead used the Python SDK instead of the API running on local host.
This works really well and is also just as easy as using the API; however, it doesn’t use the built-in chat architecture that GPT-4.org uses to make it easy to interface with these LLMs. For example, it includes conversation setup and system prompts and automatic temperature settings, so whenever you start using it, it just kind of works out of the box.
You don’t have to fathom it; however, with the Python SDK there’s no none of those niceties. So, it’s more like a raw chat model rather than a raw completions model or a chat model. The answer is less coherent.
**Note-taking Issues**
So, this was giving me problems in the content of the note, but I also abandoned using the prompt asking it to create a title because it was just confusing it further. So, for the title to generate a relevant title, I resorted to re-injecting the summarized text from the transcription that had already been through LLaMA, putting that into a new prompt and saying “generate a seven-word title” or less.
**Lama’s Response**
It will say, “Here is a summary of your text in seven words or less,” then provide the title which is also seven words long. It will also put a smiley face at the end. So, this is fantastic, but it’s just too wordy; I don’t want that for my title.
**Current Status**
However, it seems to be working given that I’ve actually dictated this entire blog post through this script and it seems to be pretty coherent and pretty good. The next stage is to write an Apple Watch app because even if I can’t get the LLaMA stuff to work using Lama, I don’t really need it.
**Apple Watch App**
All I need is a speech-to-text algorithm that’s really good. I can use the large model of Whisper because Whisper is honestly fantastic; it’s actually scary how good it is. And if I use the large model of that, then the text will be probably so coherent and so good that it doesn’t need to be cleaned up by a large language model.
**Plan**
I’ll write an Apple Watch app with just one button on it that says “make a note.” So, I can just press and hold the button, say my note, release the button, and it will send that audio recording off to my server which will transcribe and archive the note. That’s really all I need.
**Future Development**
If I can get LLaMA working as well, that would be a plus. What would be really cool is if I could get it to create links and create an interconnected web of these notes so I can kind of see like similar thoughts.
As a final conclusion, as a final note, I managed to use GPT for all of my GUI to index all of my notes from Trillium. So, I exported all 100,000 words and five years of my notes in Markdown format and set up NOMIC GPT for all indexing the entire folder. Then, I allowed GPT-3.18B with a 128K model to access the index of this local folder.
This enabled me to ask it anything about my notes, which was fantastic. Whether it’s something like “I can’t remember which dream I had four years ago but I know it had Joe Biden and Jeff Bezos in,” or if I need help remembering what was on my shopping list or the function of dual op-amps – all my knowledge is now instantly searchable at my fingertips.
If I could integrate this into a program, maybe with a text-to-speech helper, then it would be unstoppable.